Where to Cut
I read the headline — “True Multi-Agent Collaboration Doesn’t Work” — and almost scrolled past. I’ve seen enough articles where someone throws a naive prompt at an AI, gets a naive result, and concludes that AI is stupid. These pieces tell you more about the author’s assumptions than about the technology. They start with a conclusion and design an experiment to confirm it.
This was the opposite. McEntire’s paper, “The Organizational Physics of Multi-Agent AI,” did something I hadn’t seen before: a controlled experiment that reproduced every major organizational dysfunction — bikeshedding, analysis paralysis, compliance theater, governance conflict — without an organization. No humans. No egos. No career incentives. No politics. Just language models executing prompts. The dysfunction emerged from the architecture alone.
That’s when I stopped scrolling.
Your AI agent is only human#
Here’s what McEntire did. He built a multi-agent AI system to write software autonomously. Multiple specialized agents — architect, executor, reviewer, tester — organized in a pipeline, each with a clear role. He equipped the system with six explicit countermeasures against known organizational dysfunctions: anti-bikeshedding directives, factual/subjective issue classification, escalation hierarchies, scoped reviews. The system was designed, with full knowledge of organizational theory, to not fail the way human organizations fail.
It failed the way human organizations fail.
The reviewer agents rejected working code on subjective grounds — zero factual issues, 23 subjective objections, pipeline blocked. The governance hierarchy disagreed with itself: a project-level arbiter rejected what an architect-level arbiter force-approved, 28 seconds apart. The verification stage reported tests=0/0 nine consecutive times — no tests written, no tests run, no tests failed, full compliance certified. One pipeline spent its entire budget agreeing about what to build without writing a single line of code.
I am Jack’s complete lack of surprise.
If you’ve spent time in organizations of any size, you recognize every one of these patterns. The review committee that spends 45 minutes on the bike shed and 2 minutes on the reactor. The compliance process that checks the box without checking the work. The governance layer that creates more disagreements than it resolves. The planning phase that consumes the budget meant for execution.
The twist is that McEntire removed every human-specific causal factor. No ego. No fatigue. No cultural norms. No status competition. The agents were language models executing prompts. The dysfunction emerged anyway.
This isn’t just a case of AI resembling human behavior. I’ve seen that too — we recently built a scraper that got manipulated by hidden text on websites, the same way a deceptive interface misdirects a human user. Dark UI patterns, it turns out, work on agents. But that’s learned behavior, heuristics absorbed from training data. McEntire’s finding is more fundamental: the dysfunction is isomorphic. Same mathematical structure, same failure modes, same mechanisms — arising from information-theoretic constraints that apply to any system coordinating through compressed representations.
The substrate changes. The physics doesn’t.
The physics of the cut#
Why does this happen? The core insight is the Data Processing Inequality: for any chain of processing steps X → Y → Z, the information that Z has about X can never exceed the information that Y has about X. No post-processing of a compressed signal can recover what was lost at the compression stage.
Every boundary between agents — or teams, or departments, or subsystems — is a compression step. The architect produces a rich design; it’s compressed into an approve/reject verdict for the reviewer. The reviewer’s objections are compressed into a re-architecture instruction. At each step, information is irreversibly destroyed. Adding more agents, more review stages, more governance layers cannot compensate — each one introduces another compression boundary where more information is lost.
McEntire tested four architectures on the same task, with the same model and the same budget:
- Single agent (no boundaries): 28/28
- Hierarchical (one boundary layer): 18/28
- Stigmergic/concurrent (implicit boundaries): 9/28
- 11-stage pipeline (maximum boundaries): 0/28
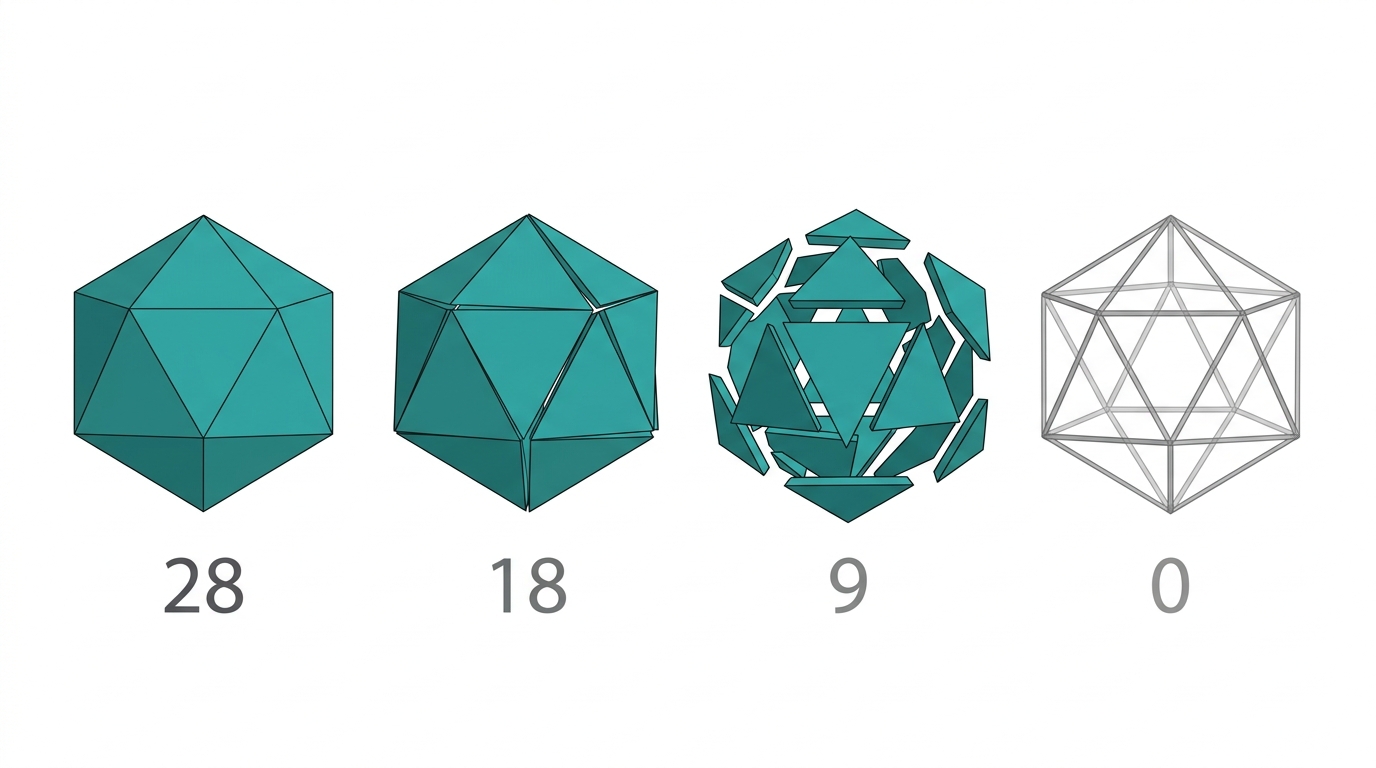
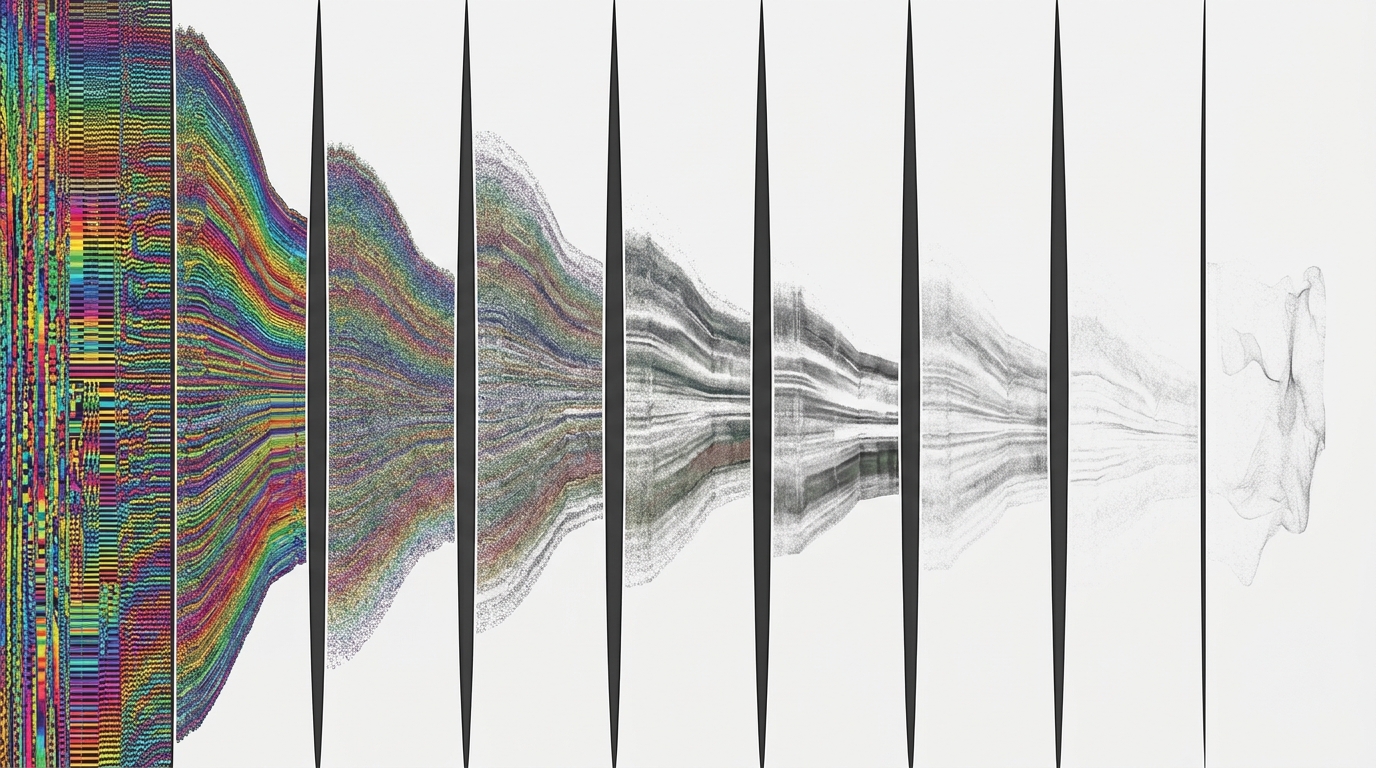
Performance degrades monotonically with the number of cuts. Cost per quality point: $1.83, $2.81, $4.88, infinity. The pipeline — the architecture with the most organizational structure — consumed its entire budget on five planning stages without producing a single file.
In 1964, Christopher Alexander published Notes on the Synthesis of Form and made essentially the same argument from design theory. A system with nine components has 72 potential interactions. But each component also has aspects — cost, weight, sourcing difficulty, how well it joints with adjacent materials. The real interaction space is combinatorial. No designer can hold it in their head. So you decompose: three subsystems of three, 18 internal interactions plus 3 cross-boundary ones. Manageable.
But Alexander understood what most engineers forget: the decomposition is not a simplification of the problem. It is the problem. Choose the wrong boundaries and you’ve created a system that can’t work — not because the components are bad, but because the interfaces between them don’t capture what matters.
The Ariane 5 disaster is the same pattern in hardware. The guidance software worked flawlessly for Ariane 4. The interface specification was precise — for the previous rocket’s flight envelope. When Ariane 5’s more powerful engines produced higher lateral acceleration, the software’s 16-bit register overflowed and the rocket self-destructed 37 seconds after launch. The software was fine. The components were fine. The interface — the boundary where one subsystem’s assumptions met another’s reality — was where the system failed. The specification had compressed the full physics into a validity range, and the compression was lossy in exactly the wrong place.
Alexander argued this from design theory. McEntire proves it from information theory. The cut is where the dysfunction lives.
A caveat before the counterexample#
I haven’t reproduced these results. McEntire’s methodology is transparent — prompts are published, audit trails are shown, and the architecture-specific pathologies are qualitatively distinct in ways that would be hard to fabricate. The paper reads as rigorous. But I’m citing specific numbers based on one author’s experiment, and the findings await independent replication. The argument in this post stands on the information-theoretic logic, not solely on one experiment — but intellectual honesty demands the caveat.
A related question: does any of this change with superhuman AI? I don’t think so. The Data Processing Inequality is mathematical — it doesn’t care how smart the processor is. An IQ-400 brain communicating through an approve/reject channel still loses everything that doesn’t fit through that channel. Smarter models raise the single-agent ceiling, which if anything makes the case for multi-agent architectures weaker, not stronger. The physics is about the boundary, not the node.
The cut that paid for itself#
I should be honest about a complication from my own practice.
A week before writing this, we restructured TenderStrike’s agent architecture from a single agent to two layers. A research agent — cheap, fast model — navigates file systems, finds relevant documents, prequalifies what matters. A SOTA model sets the research tasks and produces the final analysis. The interface is broad: the research agent returns essentially what raw tool calls used to produce, minus the dead ends.
Cost dropped noticably. Speed improved 2–3×. Quality went up — more total tool calls, less context rot per agent, natural parallelization across independent subtasks.
This is multi-agent. It works better than single-agent on every dimension.
So am I undermining my own thesis? I don’t think so, but it sharpens it.
The difference is the interface. McEntire’s architectures passed narrow signals between agents — approve/reject, compressed summaries, governance verdicts. Each boundary destroyed task-relevant information. Our research agent passes a broad interface: evidence, not judgment. The compression targets attention (which files matter), not content (what’s in them). The downstream model sees what it needs, just without having burned half its context window on noise.
That’s Alexander’s point exactly. The cut between “navigate and filter” and “analyze and reason” follows a natural seam in the problem. The information that crosses the boundary is the information the next stage actually needs.
It makes me wonder how many of McEntire’s failures were bad-cut failures rather than multi-agent failures — and whether a two-agent system with a broad, well-chosen interface would have matched the single agent on his benchmark. The experiment didn’t test that. And in hindsight, I should have thought of this earlier: the results don’t show that boundaries are always destructive. They show that narrow boundaries on judgment-laden signals are destructive. That’s a much more specific — and more useful — claim.
What this means#
The practical upshot isn’t “never decompose.” It’s that the default should be a single agent, and every boundary you add must justify the information it destroys.
Most multi-agent architectures in the current hype cycle fail this test. They’re org charts cosplaying as system design — manager agents, reviewer agents, QA agents — importing the bureaucratic structure whose dysfunction McEntire just demonstrated. They add boundaries because boundaries feel like rigor. They’re not. They’re compression, and compression has a cost.
The boundaries that actually pay for themselves follow natural seams: compute-bound vs. judgment-bound, broad search vs. deep analysis, cheap exploration vs. expensive reasoning. These aren’t organizational roles. They’re different modes of work with different cost and capability profiles — and the interfaces between them can be wide enough that the Data Processing Inequality barely bites.
If you’re building agent systems: start with one agent. When it hits a wall — context window, cost, speed — ask where the problem naturally separates and what needs to cross that boundary. If the answer is a rich, evidence-level interface along a genuine seam in the task, make the cut. If the answer is an approve/reject verdict from a reviewer agent, you’re building a bureaucracy.
Alexander knew this in 1964. The cut is the design. The only thing that’s changed is that we can prove it with information theory, watch AI reproduce sixty years of dysfunction in an afternoon — and, occasionally, find a cut so clean it makes the whole system better than the sum of its parts.